Counseling Privacy Issues and Expectations: Four Questions and a Framework
It sucks to botch privacy issues. It feels professionally bad (like, how did I not see that coming!?) and people—Twitter, the press, users, and, in extreme cases, regulators and plaintiffs’ attorneys—won’t let you forget it.

Tl;dr
It sucks to botch privacy issues. It feels professionally bad (like, how did I not see that coming!?) and people—Twitter, the press, users, and, in extreme cases, regulators and plaintiffs’ attorneys—won’t let you forget it.
Fortunately, the botching isn’t inevitable. If you systematically evaluate privacy issues, you’ll reduce the likelihood of a botch by a lot.
These four questions can help you with those evaluations:
- Is it safe?
- Is it technically legal?
- Does it match people's privacy expectations?
- If the answer is "no" to any of the above, how can we tweak it so it's OK?
I’ll set up the issue with an anecdote and breeze through the first two questions (they deserve more, but I have only so much to give). Then, I’ll dig into the third question about privacy expectations. Let’s go!
First, the anecdote. Superhuman is a $30-per-month email app and startup company. It’s also now a cautionary tale.
Superhuman was operating largely under the radar until, in June 2019, the New York Times featured it in a glowing review:

Within hours, Twitter got to work dunking:

That Tweeter followed up with a blog post titled Superhuman Is Spying on You. His beef was that, via silent read receipts, Superhuman showed when and where people were reading their email. So, if I sent you an email, I would see something like this:
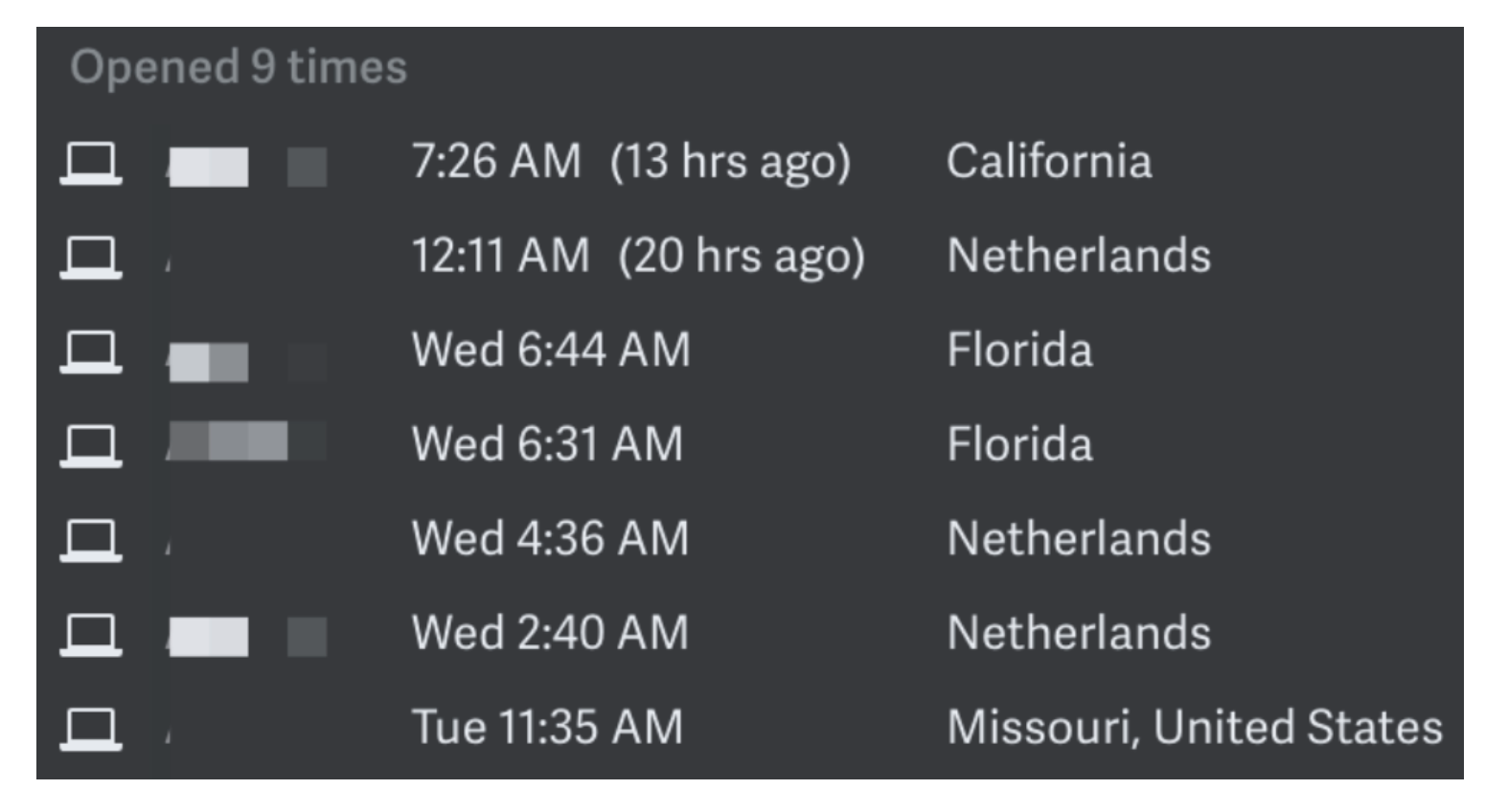
Although nobody travels from the Netherlands to Florida in two hours, so maybe not exactly like that.
Anyway, after the Tweet and blog post went viral, the mainstream media piled on (you know you’ve messed up when the New Yorker blogs about you). Which led to another entry in my favorite underrated literary genre: apologetic CEO blog posts.
Superhuman’s CEO wrote:
I am so very sorry for this. When we built Superhuman, we focused only on the needs of our customers. We did not consider potential bad actors. I wholeheartedly apologize for not thinking through this more fully.
He promised to remove the location-tracking feature but, because it was “industry standard,” kept the feature that surreptitiously tracked when, and how often, people opened each email:
We are still keeping the [read status] feature, as Superhuman is business software for email power users. In the prosumer email market, read statuses have been “must have” for many years. See MixMax, Yesware, Streak, Hubspot, and Mailtrack.
This led to another critical blog post but much less public outrage because, without the location-tracking part, people seemed not to care so much. The feature persists and is advertised on Superhuman’s website:

Anecdote over.
The four (easy?) steps to solving privacy issues
When we counsel privacy issues, we answer four questions:
- Is it safe?
- Is it technically legal?
- Does it match people’s privacy expectations?
- If the answer is no to any of the above, how can we tweak it so it’s OK?
Question 1: Is it Safe?
There’s much more to say about this, but the brief version is this: Imagine the worst human. Now imagine that worst human using your product to cause financial, physical, or legally-cognizable psychological harm. Can they?
When you ask this question of Superhuman’s location-revealing feature, the answer to question 1—is it safe?—is clearly no. It’s easy to imagine a stalker situation in which someone is put at risk by revealing their location, even if location is obfuscated to the city level.
On the other hand, I’m not aware of how time-based read receipt might put anyone’s safety at risk.
Question 2: Is it Technically Legal?
Again, for the sake of brevity, I won’t address that here but the nice thing is that you can rely on outside counsel to do an adequate job of this.
As far as Superhuman’s location-tracking feature is concerned, it is illegal under both the GDPR and Section 5 of the FTC Act. On the other hand, whether Superhuman’s time-based read receipts are legal depends on the balance of privacy interests. That one is unclear.
Question 3: Does it Match People’s Privacy Expectations?
Lawyers typically evaluate privacy expectations using their intuition and experience. This leads them to say, to the frustration of PMs and execs, things like, “This feels creepy so we shouldn’t do it.” While this intuition-based approach can often work, it can also lead to highly subjective takes.
Here, I propose a systematic framework you can use instead to evaluate privacy expectations. I apply it to Superhuman’s read receipts. But first, a word about why we care.
Exceeding privacy expectations creates legal risk.
Privacy laws are like the disinfectant wipes at a 24 Hour Fitness—rarely used and mostly decorative. Most companies freely admit they aren’t GDPR compliant because it isn’t particularly efficient to be in perfect compliance. E.g., we’re two years in to the GDPR and we have seen almost no enforcement.
But that doesn’t mean privacy doesn’t matter. Legal issues abound if we trigger enough outrage. In fact, if we really piss people off, the legalities don’t matter—regulators, partners, or plaintiffs’ attorneys will find a way to get you.
That’s why the Sears Holdings FTC consent decree is such a great precedent. To recap, Sears asked customers to install a program that tracked all of their web activity. And they told users how invasive it was in its privacy policy. This is what everyone thought they were supposed to do, yet the FTC said “not good enough” and brought the regulatory pain.
Some additional examples of privacy-expectation-exceeding products that triggered retractions:
- Facebook’s app that paid people to monitor their Internet usage (per Stratechery): “The sign-up site did state that Facebook will be able to collect large amounts of information, included encrypted communication (the TechCrunch post quotes the site), but it is fair to wonder to what extent people understood the degree of access they were granting.” Facebook discontinued the app.
- Google Street View: Driving around taking pictures of streets North American’s privacy expectations in the United States. Not the case for Germans, where a cycle of outrage caused Google to abandon the practice there. See Habeas Data by Cyrus Farivar at xv.
- Evernote AI: Evernote’s proposal to let its employees review user content to improve the AI did not match users’ privacy expectations. It didn’t make a difference that Evernote addressed some of the potential harm by allowing people to opt out and that it satisfied its legal obligations by notifying users. Evernote abandoned the plan.
A framework for evaluating privacy expectations
Here are the steps we’ll use to evaluate privacy expectations:
- Find relevant FTC consent decrees and press scandals
- Evaluate the state of the industry
- Adjust for your product’s privacy expectations
- Segment your users into useful categories
- Adjust for your company’s privacy reputation
- Explain yourself
- If everything looks OK, then check your work
Step 1: Find relevant FTC consent decrees and press scandals.
To counsel privacy expectations, we start with the privacy-related FTC consent decrees and the scandals. If there’s bad precedent for our proposed product or feature, tread carefully.
How do we find this precedent? There aren’t many privacy-related FTC consent decrees (I’m excluding the COPPA- and HIPAA-specific ones). From memory, Snapchat, Google, Google, Facebook, Facebook, Uber, and Sears.
The privacy-related news stories are harder to track but there are ways to go find them. To track what’s happening recently, IAPP Daily Dashboard, Techdirt, and Google News alerts will all give you the latest privacy stories.
Going backwards, you can use search terms like “[company name] and privacy and (furor or investigation or controversy).” For example:

Eric Goldman’s blog has also tracked privacy issues over time.
Step 2: Evaluate the state of the industry.
Understanding how competitor products behave goes a long way in setting privacy expectations. For example, if all email clients require confirmation before sending a read receipt, then it’s likely that hidden read receipts raise privacy issues. Which isn’t to say that this fact is definitive, but it’s a key clue to what people expect.
One word of caution: If you’re an established company, emulating a tiny competitor that’s taking an aggressive position is a recipe for disaster. Small startups take risks that established companies would be wise to avoid. It’s very likely these startups haven’t properly vetted their product decisions for privacy issues (see, e.g., Superhuman).
Step 3: Adjust for your product’s particular privacy expectations.
People have higher expectations for the way you treat their documents and messages than their social media accounts, for example. That’s why people were outraged when Evernote announced employees may access anonymized content to improve their algorithms, but they didn’t bat an eye when Facebook employees could access user accounts at will.
Step 4: Segment your audience into useful categories.
Users’ expectations of privacy diverge widely. While that makes it challenging to counsel privacy expectations, it’s possible to segment users into useful groups and then evaluate the privacy expectations of each group.
For example, business users tend to have lower privacy expectations than personal users. Maybe that’s because employees, in the U.S. at least, tend to take for granted that their employers are spying on them. Or maybe that’s because while they may be dealing with sensitive information, like future product plans, that information isn’t as sensitive as the messages they send to their spouses. (Practice tip: If you have users sign up to your service with email addresses, you can determine (but not with absolute certainty) whether they’re on a personal domain (jane@gmail.com) or a business one (jane@ibm.com)).
Here are some other useful ways to segment your audience:
- Users versus non-users
- Europeans versus North Americans
- Paid versus free users
- Younger users versus older users
Step 5: Adjust for your company’s privacy reputation.
Depending on your company’s reputation, users may give you the benefit of the doubt, or they may distrust you so much that they’ll find fault with you no matter what you do.
From Stratechery:
Consider the Portal, which was developed by Facebook itself; by all accounts the video calling device, which tracks callers as they move around the room, and which recently added a version that attached to your TV, works extremely well. . . .
And yet Portal is basically a non-entity in the market; according to IDC Facebook has shipped around 54,000 units since it was launched, which is far less than 1% of the market. There are certainly structural explanations — hardware requires distribution channels and completely new go-to-markets, and Google has gone through similar learning curves when it comes to selling hardware — but there’s also the reputational one: does anyone actually want a Facebook-built camera and microphone in their house?
Step 6: Explain yourself.
As I mentioned, apologetic blog posts are common in the wake of a privacy debacle. My advice: Instead of waiting for something to go wrong, write it before you launch the product.
This serves two purposes. First, writing forces you to contend with the potential criticisms. If your best rationale doesn’t write well, then you likely haven’t sufficiently addressed the privacy issues with the project. Second, as soon as you launch, you can release what you write in the form of a FAQ or Help Center article and address some of your critics in advance.
Step 7: If everything looks OK, then check your work.
Once we’re satisfied that our product is OK to launch, we can sanity-check our analysis by:
- Testing a less privacy-intrusive version of the product or feature;
- Slowly rolling out the product or feature in limited geographies or to a small number of users;
- Performing user research and informal focus groups; and
- Reaching out to privacy-focused non-profits like the EFF or the Center for Democracy & Technology.
Using the Framework Part 1: Superhuman’s Location Tracking
In almost all cases, including opening emails, tracking consumers’ location fails all the tests. It isn’t safe, it’s not legal, and there’s privacy-scandal precedent directly on point.
However, all of that applies in the consumer, as opposed to the business, context. When we go to the fourth step and think about tweaks, one possibility worth considering is whether Superhuman could limit the location-tracking feature to recipients of mass- or templated-emails on business domains.
The reason that *might* work is because of the reduced privacy expectations that people have at work and in response to marketing and newsletter emails. For those users and use cases, it’s more difficult to find a safety issue or a violated privacy expectation.
Using the Framework Part 2: Superhuman’s Surreptitious Read-time Tracking
We’ll go through each step of the expectations framework in turn:
- Find relevant FTC consent decrees and press scandals: There’s nothing on point.
- Evaluate the state of the industry: Surreptitious read-time tracking is standard in marketing email products but not consumer ones. For example, GMail and Outlook both ask the recipient if they want to respond to the read-receipt request. Because Superhuman is for both business and consumer users, enabling surreptitious read-time tracking is out of line with the industry.
- Adjust for your product’s privacy expectations: This step doesn’t help us because the recipients don’t know they are receiving a Superhuman-sent email.
- Segment your users into useful categories: The people Superhuman should be most worried about are Germans on personal email addresses for personal purposes.
- Adjust for your company’s privacy reputation: Because Superhuman operates relatively under the radar, as compared to, say, Google, it can take more daring privacy approaches.
- Explain yourself: I can’t think of a good explanation as to why a sender should know when, and how many times, the recipient of a personal email opened it. Therefore, it doesn’t write.
- If everything looks OK, then check your work: Superhuman could have launched this feature to North American senders only, under the theory that they’re most likely to correspond with other North Americans. Then, if the reaction was positive or neutral, Superhuman could have released it more broadly.
This is a close call. Step 6 is where I get stuck. It just doesn’t write. So, because the value of the read receipts is in business uses, not personal ones, I would’ve advised Superhuman to limit the feature to recipients on business domains.
Question 4: If the answer is no to any of the above, how can we tweak it so it’s OK?
Now that we’ve gone through the full analysis of Question 3—does it match users’ privacy expectations—we can move on to the last question. I would’ve advised Superhuman to limit the feature to recipients on business email addresses or, if that significantly delayed the launch, to do that soon after.
If Superhuman had limited both location- and read time-tracking to mass- or templated-emails directed at business recipients only, it might have avoided the Twitter furor and bad press and kept these features intact.
Additional Thoughts
- Outside counsel are typically poor at counseling privacy expectations, but it’s not their fault. They don’t get asked to do it very often and, if they do get asked, they don’t have sufficient context to do it well.
- Everyone at your company will have an opinion about privacy expectations. Those can be useful inputs but should not be determinative unless they’ve thought deeply about privacy expectations systematically.
Thank you, thank you, thank you to the friends and family who read this post and gave me comments. All errors are my own, but everything they suggested made it better.